CognEn
Cognitive Engagement Analyzer
v1.0 Browser Next.js 15 · Webcam · Chrome Extension v2.0 Server Python FastAPI · Multi-person CCTV
(hybrid real-world test set)
(isolated classifier)
(v2.0 dense environments)
(hybrid dataset, 6 classes)
"Context-Gate Override, ConfusionPenaltyLoss, and AR(1) temporal autocorrelation resolve critical failure modes documented in state-of-the-art engagement monitoring literature — yielding +12.4% precision for using_phone, +18.5% macro-F1, and temporal consistency 0.742 → 0.931."
— CognEn README, Novel Algorithmic Contributions
01 — Overview
Two Deployments, One ML Core
The Problem
Existing engagement monitoring systems apply a uniform downward-gaze penalty that cannot distinguish a student reading a book (attentive) from a student texting on their phone (distracted) — the biometric signals are visually homologous.
Rule-based spatial heuristics (the prior state of the art) achieve only 80.8% accuracy and fail under partial occlusion and object-detector failures. Networks trained without structured temporal data barely exceed random chance (21.3% on a 6-class problem vs 16.7% chance).
The Approach
CognEn resolves biometric ambiguity through five novel algorithms: context-conditional scoring with hard-rule post-processing, an asymmetric loss function penalizing high-cost pedagogical errors, AR(1) temporal fusion for sustained behavioral continuity, a Shapely-based prioritized seat mapper, and rolling-window OLS fatigue onset detection.
The result: 86.5% behavior accuracy on a hybrid real-world test set — +5.7% over the deterministic spatial baseline — while the temporal consistency coefficient improves from 0.742 to 0.931.
v1.0 vs v2.0 — System Comparison
| Feature | v1.0 Browser | v2.0 Server |
|---|---|---|
| Primary Target | Single student, desk webcam | Classroom, multi-student CCTV |
| Input Source | 640×480 @ 5 FPS webcam | 1280×720 RTSP / file / USB |
| Tracking | Single person (first detected face) | Multi-person (ByteTrack MOT) |
| Face Detection | face-api.js TinyFaceDetector | YOLOv8-m (person) + MediaPipe FaceMesh |
| Object Detection | YOLOv8-nano ONNX (WebGPU/WASM) | YOLOv8-s (PyTorch/GPU) |
| Behavior Classifier | 1D-CNN ONNX (browser runtime) | 1D-CNN ONNX (server runtime) |
| Pipeline Throughput | ~125 ms/frame | ~35 ms/frame (~28 FPS) |
| Classifier Latency | <0.02ms/subject | <0.02ms/subject |
| Output | Dashboard + PDF report + Firebase | Room analytics WebSocket @ 5Hz |
| Extension | Chrome MV3 (Google Meet / Zoom) | — |
| Seat Mapping | — | Shapely polygon IoU (96.3% accuracy) |
02 — Architecture
Pipeline Architecture
v1.0 — Browser Pipeline Next.js 15
v2.0 — Server Pipeline FastAPI + GPU
6 Behavior Classes
03 — Visuals
Screenshots
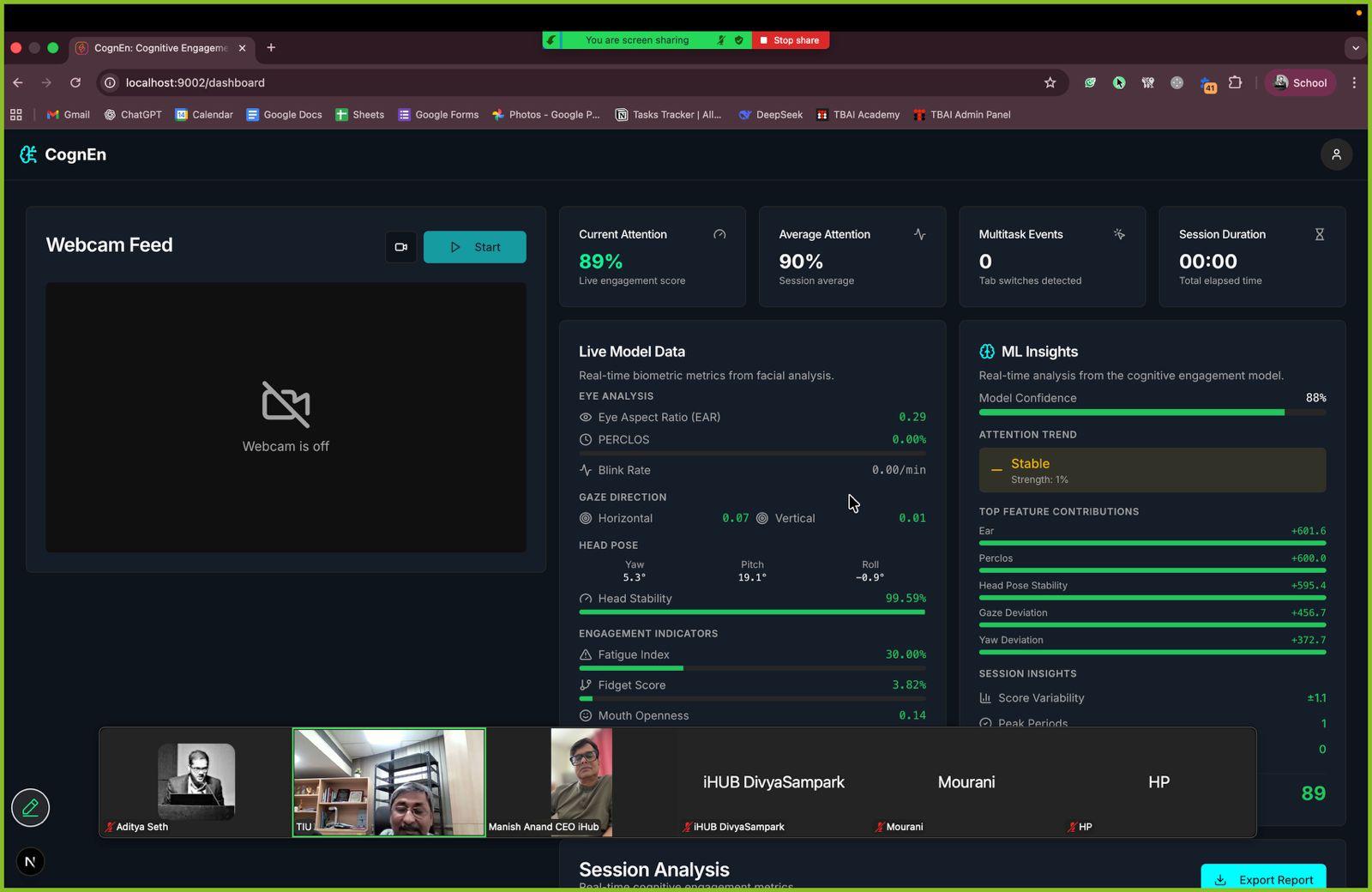
v1.0 · Google Meet · Live Dashboard Share
v1.0 · Google Meet · Active Session View
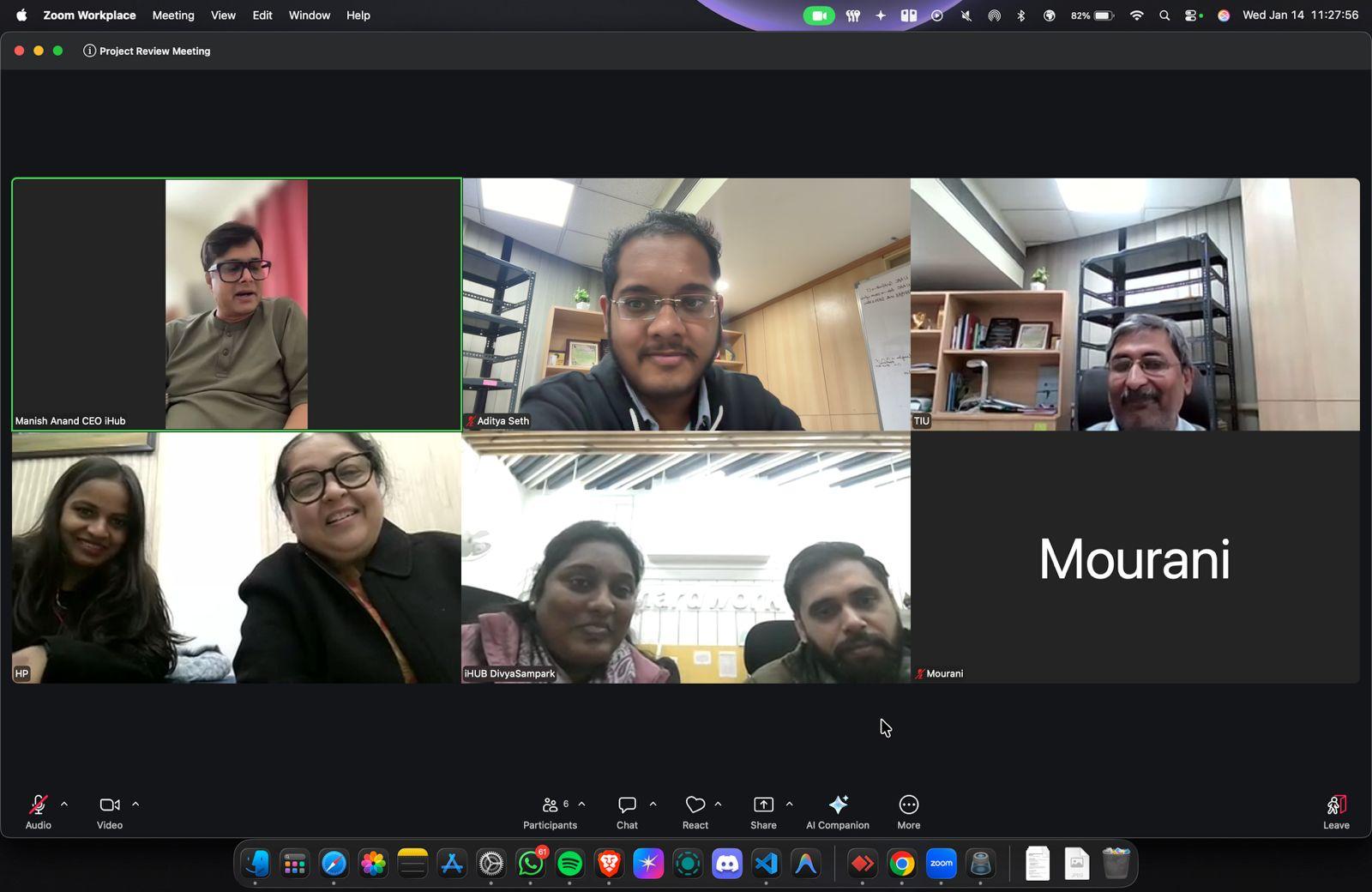
v1.0 · Zoom Integration · Multi-person Conference
v1.0 · Zoom Integration · Active Meeting View
04 — Novel Contributions
5 Novel Algorithms
using_phone over attentive_reading when a phone object and hand interaction are detected in close proximity).3.0× penalty multiplier if the model predicts "reading" when the student is actually using a "phone" (a high-cost pedagogical error), while standard 1.0× multipliers apply to less critical misclassifications. Standard cross-entropy treats all errors equally — this function does not. Uses label smoothing 0.05 and AdamW with cosine annealing.gazeDeviation: 0.12, temporalPattern: 0.03). The final 0–100 engagement score is smoothed via Exponential Moving Average with decay factor α=0.15, eliminating high-frequency state oscillation.< -0.5, high fit confidence R² > 0.4, and average score drop below < 60. All three conditions must hold simultaneously to avoid false positives from transient dips.05 — ML Core
1D-CNN Architecture & Dataset
1D-CNN Temporal Classifier
A 3-layer Convolutional Neural Network (1D) evaluates a sliding window of 15 frames (3 seconds at 5 FPS) to classify the current behavioral state. Parameters: ~20,550 — lightweight enough for browser ONNX runtime (WebGPU → WASM fallback).
(Batch, 13, 15)
+ BatchNorm
+ BatchNorm
+ BatchNorm
Pooling
Softmax
Probabilities
Dataset Specification — 55,100 Annotated Sequences
A hybrid dataset combining class-conditional synthetic sequences with real-world annotated clips to introduce lighting variance, partial occlusion, and detection jitter.
Augmentation strategy: Temporal time-warping (±20%), localised feature dropout (8%), Gaussian gaze jitter (σ=0.05), targeted object-context injection. Each 15-frame window = 3 seconds of behaviour at 5 Hz sampling.
Feature preprocessing: Gaze and yaw/pitch angles normalised to [−1, 1]. Biometrics (EAR, PERCLOS) clamped to [0, 1]. Object semantics mapped to one-hot vectors. Hand-object interactions encoded as continuous proximity coefficients.
06 — Validation
Performance Metrics
Ablation Study — Component Penalties
| Component Removed | Impact | Magnitude |
|---|---|---|
| Context-Gate Override | Reintroduces biometric ambiguity (phone vs. reading) | −12.4% precision (using_phone) · −9.1% recall (attentive_reading) |
| ConfusionPenaltyLoss → standard cross-entropy | Removes optimisation of pedagogical edge-cases | −18.5% macro-F1 |
| AR(1) Temporal Autocorrelation | Model flickers between transient states | Temporal consistency: 0.931 → 0.742 (−0.189) |
Baseline Comparisons
| Baseline Method | Accuracy | Failure Mode |
|---|---|---|
| Naive Temporal (1D-CNN, uniform sequences) | 21.3% | Network topology alone is insufficient without structured temporal data (random chance = 16.7%) |
| Deterministic Spatial Heuristic (rule-based) | 80.8% | Severe degradation under partial occlusion and object-detector failures |
| CognEn (proposed) | 86.5% | +5.7% over heuristic baseline; robust to occlusion via Context-Gate |
07 — Stack
Technology Stack
v1.0 — Browser Stack Next.js 15
v2.0 — Server Stack FastAPI + GPU
Privacy & Security: No raw video stored — only derived feature vectors and metrics are persisted. All inference runs locally (in-browser for v1.0, on local GPU for v2.0). Track IDs (not names) are used by default in v2.0. Analytics auto-purge after 24 hours. The system never transmits raw video to any external service.